3. Pandas 快速上手:玩转表格数据
本章,你将学到:
-
核心数据结构:理解
Series(一维序列) 和DataFrame(二维数据框)。 -
数据导入与导出: 轻松读写
CSV和Excel文件。 -
数据筛选与查询: 掌握
loc,iloc和布尔索引,像 SQL 一样查询数据。 - 数据清洗: 处理缺失值、重复值和转换数据类型。
-
分组与聚合: 使用
groupby进行数据分组并计算统计量。 -
数据合并与重塑: 掌握
merge,join,concat和pivot_table。
温馨提示
配套资源:本章所有代码和配套资源可以点击如下连接下载——练习 Notebook 和 示例数据集 sales_data.csv。下载好后,同学可以在自己的 Anaconda 环境内运行这些代码,这有助于你们快速掌握相关内容。
Pandas: Python 世界的 Excel
如果说 NumPy 是处理数值数组的专家,那么 Pandas 就是处理表格数据(tabular data)的王者。在商业分析和数据科学领域,我们遇到的大部分数据都是结构化的二维表格,就像 Excel 表格一样。Pandas 的设计初衷就是让 Python 拥有强大、灵活、易用的数据清洗和分析能力。
为什么 Pandas 如此核心?
-
直观的数据结构: Pandas 的
DataFrame对象与我们熟悉的电子表格或数据库表非常相似,易于理解和操作。 - 强大的 I/O 功能: 只需一行代码,就能轻松读取 CSV、Excel、SQL 数据库等多种来源的数据。
- 丰富的数据操作: 它提供了海量的方法,用于数据筛选、清洗、转换、合并、重塑等,几乎能满足所有数据预处理需求。
- 与生态无缝集成: Pandas 与 NumPy、Matplotlib、Scikit-learn 等库紧密集成,是整个数据科学生态的“数据中枢”。
本章将带你掌握 Pandas 最常用、最重要的核心功能。
有用链接:
准备工作
在开始之前,我们需要导入 Pandas 库。业界惯例是将其重命名为 pd。同时,我们也会导入 NumPy,因为 Pandas 大量依赖于它。
import pandas as pd
import numpy as np
一、核心数据结构:Series 与 DataFrame
1. Series: 带标签的一维数组
Series 是一个类似于一维数组的对象,但它有一个额外的标签(Index),可以让我们用标签而不是数字位置来访问元素。你可以把它想象成一个只有一列的 Excel 表格,其中一列是数据,另一列是行索引。
pd.Series(data=None, index=None, dtype=None, name=None)
| 参数 | 说明 |
|---|---|
data |
(可选)输入的数据,可以是列表、字典、标量等。 |
index |
(可选)自定义标签索引,长度需与数据匹配。 |
dtype |
(可选)指定数据类型,默认会自动推断。 |
name |
(可选)为 Series 命名,便于在结果中识别。 |
# 从列表创建一个 Series,Pandas 会自动创建从 0 开始的整数索引
s = pd.Series([10, 20, 30, 40, 50])
print("一个简单的 Series:")
print(s)
# 你也可以在创建时自定义索引、数据类型以及名称
s_custom_index = pd.Series([10, 20, 30], index=['a', 'b', 'c'], dtype='float64', name='scores')
print("\n带自定义索引的 Series:")
print(s_custom_index)
# 通过索引访问数据
val = s_custom_index['b']
print(f"\n获取索引为 'b' 的值: {val}")
2. DataFrame: 带标签的二维表格
DataFrame 是 Pandas 的核心,它是一个二维的、大小可变的、异构的表格数据结构,拥有带标签的行(index)和列(columns)。你可以把它看作一个 Excel 工作表、一个 SQL 表,或者一个由多个 Series 共享相同索引组成的字典。
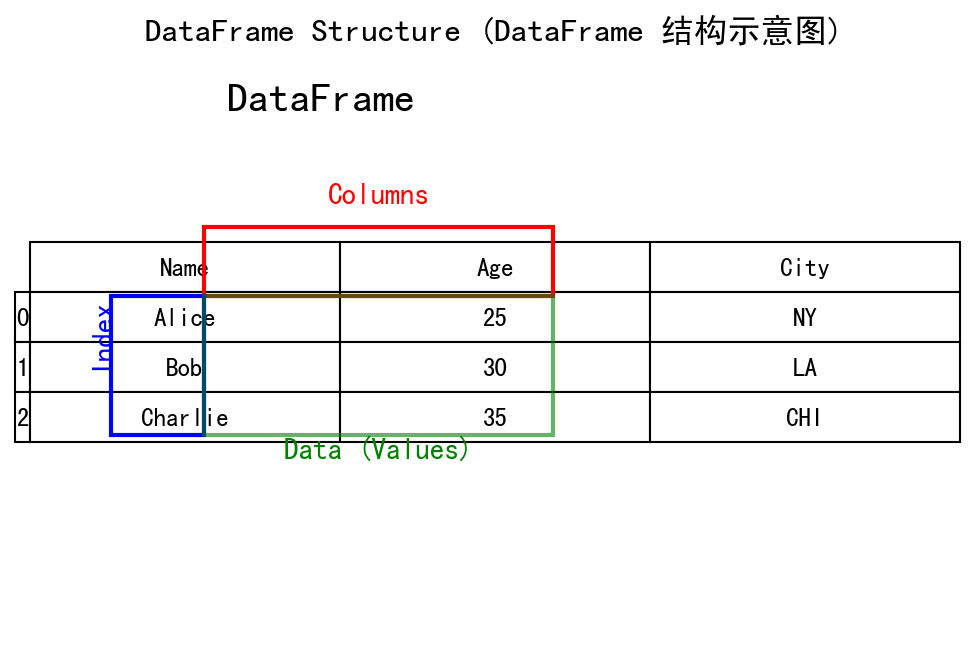
pd.DataFrame(data=None, index=None, columns=None, dtype=None)
| 参数 | 说明 |
|---|---|
data |
(可选)数据源(字典、二维数组、Series 字典等)。 |
index |
(可选)行索引标签,长度需与行数一致。 |
columns |
(可选)列索引标签,长度需与列数一致。 |
dtype |
(可选)指定统一的数据类型。 |
# 从一个字典创建 DataFrame,字典的 key 会成为列名
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data, index=['R1', 'R2', 'R3', 'R4'])
print("一个简单的 DataFrame:")
print(df)
二、数据导入与导出:连接现实世界
数据分析的第一步通常是加载数据。Pandas 提供了强大而易用的函数来读取各种格式的文件。
[Data Placeholder: sales_data.csv; columns: Date, Category, Product, Sales, Region]
1. 读取 CSV 和 Excel 文件
-
pd.read_csv(): 读取逗号分隔值(CSV)文件,这是最常用的数据格式。 -
pd.read_excel(): 读取 Excel 文件 (.xls或.xlsx)。注意,使用此功能可能需要额外安装openpyxl库 (pip install openpyxl)。
pd.read_csv(filepath_or_buffer, sep=',', usecols=None, parse_dates=None, dtype=None, index_col=None)
| 参数 | 说明 |
|---|---|
filepath_or_buffer |
(必选)文件路径或类文件对象。 |
sep |
(可选)分隔符,默认逗号,可改为制表符等。 |
usecols |
(可选)只读取指定列,减少内存使用。 |
parse_dates |
(可选)指定需要解析为日期的列。 |
dtype |
(可选)指定列的数据类型,避免自动推断错误。 |
index_col |
(可选)指定列作为行索引。 |
pd.read_excel(io, sheet_name=0, usecols=None, dtype=None, engine=None)
| 参数 | 说明 |
|---|---|
io |
(必选)Excel 文件路径或缓冲区。 |
sheet_name |
(可选)工作表名称或索引,默认第一个。 |
usecols |
(可选)只读取指定列。 |
dtype |
(可选)指定列数据类型。 |
engine |
(可选)指定读写引擎,如 openpyxl。 |
# 假设我们有一个名为 'sales_data.csv' 的文件
# df = pd.read_csv('sales_data.csv', usecols=['Date', 'Sales', 'Region'], parse_dates=['Date'], dtype={'Sales': 'float64'})
# 为了让示例可复现,我们先在内存中创建一个模拟的 DataFrame
sales_data = {
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-03'],
'Category': ['Electronics', 'Books', 'Electronics', 'Books', 'Electronics'],
'Product': ['Laptop', 'Novel', 'Mouse', 'Poetry', 'Keyboard'],
'Sales': [1200, 30, 50, 25, 150],
'Region': ['East', 'West', 'East', 'West', 'East']
}
df_sales = pd.DataFrame(sales_data)
print("模拟的销售数据 DataFrame:")
print(df_sales)
# 读取 Excel 示例
# df_excel = pd.read_excel('sales_data.xlsx', sheet_name='January', usecols='A:E')
2. 快速检视数据
加载数据后,我们通常会做一些快速的探索性检查。
| 方法 | 常用参数 | 说明 |
|---|---|---|
df.head(n=5) |
n(可选): 返回的行数 |
查看前几行,快速了解数据结构。 |
df.tail(n=5) |
n(可选): 返回的行数 |
查看末尾几行是否存在缺失或异常。 |
df.info(verbose=None, memory_usage=None) |
memory_usage(可选): 统计内存占用;verbose(可选): 控制输出细节 |
获取列类型、非空计数以及内存使用。 |
df.describe(percentiles=None, include=None, exclude=None) |
include(可选): 指定包含的列类型;exclude(可选): 排除特定列类型;percentiles(可选): 自定义百分位 |
生成描述性统计,支持数值和类别数据。 |
# 查看前 3 行(使用命名参数更清晰)
head_view = df_sales.head(n=3)
print("\n前 3 行数据:")
print(head_view)
# 查看最后 2 行
tail_view = df_sales.tail(n=2)
print("\n最后 2 行数据:")
print(tail_view)
# 查看数据信息摘要
print("\n数据信息摘要:")
df_sales.info(memory_usage='deep')
# 查看描述性统计
desc_stats = df_sales.describe(include='all')
print("\n描述性统计:")
print(desc_stats)
3. 导出数据
分析完成后,你可能需要将处理好的数据保存到新文件中。
| 方法 | 常用参数 | 说明 |
|---|---|---|
df.to_csv(path_or_buf, index=False, columns=None, encoding='utf-8', compression=None) |
path_or_buf(可选): 输出路径或缓冲区;index(可选): 是否写入索引;columns(可选): 选择导出的列;encoding(可选): 指定编码;compression(可选): 压缩格式 |
导出为 CSV 文件或缓冲区。 |
df.to_excel(excel_writer, sheet_name='Sheet1', index=False, columns=None, engine=None) |
excel_writer(必选): 输出路径或缓冲区;sheet_name(可选): 工作表名称;engine(可选): 指定写入引擎(如 openpyxl);columns(可选): 选择导出的列 |
导出为 Excel 文件或缓冲区。 |
# 导出为 CSV(不会包含索引列),只保留常用字段
df_sales.to_csv('sales_export.csv', index=False, columns=['Date', 'Product', 'Sales'])
# 导出为 Excel(需要安装 openpyxl),示例中保留全部列
# df_sales.to_excel('sales_export.xlsx', index=False, sheet_name='Sales Summary', engine='openpyxl')
三、选择与过滤:像 SQL 一样查询
从庞大的数据集中精确地提取你需要的行和列,是数据分析的核心技能。
1. 选择列
-
使用
[]: 最简单的方式,类似于字典的 key 索引。 -
使用
.: 如果列名是有效的 Python 标识符(没有空格、特殊字符),可以用点号访问。
| 语法 | 返回对象 | 说明 |
|---|---|---|
df['col'] |
Series |
根据列标签选择单列。 |
df[['col1', 'col2']] |
DataFrame |
使用列表选择多列。 |
df.col |
Series |
语法糖,仅当列名符合标识符规则时可用。 |
# 选择单列,返回一个 Series
sales_column = df_sales['Sales']
print("\n选择 'Sales' 列 (Series):")
print(sales_column)
# 选择多列,返回一个新的 DataFrame
selected_cols = df_sales[['Date', 'Product', 'Sales']]
print("\n选择 'Date', 'Product', 'Sales' 三列 (DataFrame):")
print(selected_cols)
2. 使用 loc 和 iloc 进行选择
[] 在选择行时有歧义,因此 Pandas 提供了更明确的索引器:loc 和 iloc。
-
df.loc[]: 基于标签 (Label) 的选择。它使用行和列的名称来选择数据。 -
df.iloc[]: 基于整数位置 (Integer location) 的选择。它使用行和列的数字索引(从 0 开始)来选择数据。
df.loc[row_indexer, column_indexer]
| 参数 | 说明 |
|---|---|
row_indexer |
(必选)行标签、切片、布尔数组或索引器对象。 |
column_indexer |
(可选)列标签或切片,省略时返回所有列。 |
df.iloc[row_indexer, column_indexer]
| 参数 | 说明 |
|---|---|
row_indexer |
(必选)行的整数位置或切片。 |
column_indexer |
(可选)列的整数位置或切片。 |
# --- 使用 loc ---
# 选择索引为 1 的行
row_1_loc = df_sales.loc[1]
print(f"\n使用 loc 选择第 2 行:\n{row_1_loc}")
# 选择索引为 1 到 3 的行,以及 'Product' 和 'Sales' 列
subset_loc = df_sales.loc[1:3, ['Product', 'Sales']]
print(f"\n使用 loc 选择特定行和列:\n{subset_loc}")
# --- 使用 iloc ---
# 选择第 2 行 (位置为 1)
row_1_iloc = df_sales.iloc[1]
print(f"\n使用 iloc 选择第 2 行:\n{row_1_iloc}")
# 选择第 2-3 行 (位置 1, 2),以及第 3-4 列 (位置 2, 3)
subset_iloc = df_sales.iloc[1:3, 2:4]
print(f"\n使用 iloc 选择特定行和列:\n{subset_iloc}")
3. 布尔索引 (Conditional Filtering)
这是最强大、最常用的筛选方式。它允许你根据一个或多个条件来过滤行。
| 方法 | 常用参数 | 说明 |
|---|---|---|
Series > value |
任意比较运算符 | 基于阈值的筛选。 |
(cond1) & (cond2) |
&, |, ~
|
组合多个布尔条件时需要括号。 |
Series.isin(values) |
values: 可迭代对象 |
判断元素是否属于给定集合。 |
Series.between(left, right, inclusive='both') |
left, right, inclusive
|
按区间筛选数值范围。 |
# 1. 找出销售额大于 100 的所有记录
high_sales_mask = df_sales['Sales'] > 100
high_sales_df = df_sales[high_sales_mask]
print(f"\n销售额大于 100 的记录:\n{high_sales_df}")
# 2. 组合多个条件:找出 'East' 地区且销售额大于 100 的记录
# 注意:多个条件必须用 & (与) 或 | (或) 连接,并且每个条件都要用括号括起来
east_high_sales_mask = (df_sales['Region'] == 'East') & (df_sales['Sales'] > 100)
east_high_sales_df = df_sales[east_high_sales_mask]
print(f"\nEast 地区且销售额大于 100 的记录:\n{east_high_sales_df}")
# 3. 使用 isin() 筛选 'Category' 是 'Books' 或 'Clothing' 的记录
# (我们的示例数据没有 Clothing,但演示了用法)
books_or_clothing_mask = df_sales['Category'].isin(['Books', 'Clothing'])
books_or_clothing_df = df_sales[books_or_clothing_mask]
print(f"\n类别为 'Books' 或 'Clothing' 的记录:\n{books_or_clothing_df}")
# 4. 使用 between() 筛选指定区间范围
mid_sales_mask = df_sales['Sales'].between(left=20, right=200, inclusive='both')
mid_sales_df = df_sales[mid_sales_mask]
print(f"\n销售额在 20 到 200 之间的记录:\n{mid_sales_df}")
四、数据清洗:让数据变得可用
真实世界的数据很少是完美的,通常充满了缺失值、重复值或错误的数据类型。数据清洗是数据分析流程中至关重要的一步。
1. 处理缺失值
首先,我们需要创建一个带缺失值(np.nan)的 DataFrame。
df.dropna(axis=0, how='any', subset=None, inplace=False)
| 参数 | 说明 |
|---|---|
axis |
(可选)沿哪个轴删除缺失值(0=行,1=列)。 |
how |
(可选)'any' 表示任一缺失即删除,'all' 表示整行/列全缺失才删除。 |
subset |
(可选)只在指定列上检查缺失。 |
inplace |
(可选)是否直接修改原对象。 |
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
| 参数 | 说明 |
|---|---|
value |
(可选)用于填充的标量、字典或 Series。 |
method |
(可选)使用 'ffill' 或 'bfill' 沿轴方向填充。 |
axis |
(可选)指定沿行或列填充。 |
limit |
(可选)限制连续填充的次数。 |
inplace |
(可选)是否直接在原对象上修改。 |
data_with_nan = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [10, 20, 30, 40]
}
df_nan = pd.DataFrame(data_with_nan)
print(f"带缺失值的 DataFrame:\n{df_nan}")
# 检查每列的缺失值数量
missing_counts = df_nan.isnull().sum()
print(f"\n每列的缺失值数量:\n{missing_counts}")
# --- 处理策略 ---
# 策略1: 删除包含缺失值的行
df_dropped = df_nan.dropna(axis=0, how='any')
print(f"\n删除所有含缺失值的行后:\n{df_dropped}")
# 策略2: 用一个特定值(如 0)填充所有缺失值
df_filled_zero = df_nan.fillna(value=0)
print(f"\n用 0 填充所有缺失值后:\n{df_filled_zero}")
# 策略3: 用每列的平均值填充该列的缺失值
mean_A = df_nan['A'].mean()
df_filled_mean = df_nan.fillna(value={'A': mean_A, 'B': df_nan['B'].mean()})
print(f"\n用列均值填充缺失值后:\n{df_filled_mean}")
# 策略4: 使用前向填充,限制连续填充次数
df_filled_ffill = df_nan.fillna(method='ffill', limit=1, axis=0)
print(f"\n前向填充(limit=1)后的结果:\n{df_filled_ffill}")
2. 处理重复值
df.duplicated(subset=None, keep='first')
| 参数 | 说明 |
|---|---|
subset |
(可选)指定用于识别重复的列集合。 |
keep |
(可选)'first' 保留首次出现,'last' 保留最后一次,False 标记所有重复。 |
df.drop_duplicates(subset=None, keep='first', inplace=False)
| 参数 | 说明 |
|---|---|
subset |
(可选)与 duplicated 相同,控制比较的列。 |
keep |
(可选)控制保留哪一个重复值。 |
inplace |
(可选)是否就地修改。 |
data_with_dups = {
'ID': [1, 2, 2, 3],
'Name': ['A', 'B', 'B', 'C']
}
df_dups = pd.DataFrame(data_with_dups)
print(f"\n带重复值的 DataFrame:\n{df_dups}")
# 检查是否为重复行
is_duplicate = df_dups.duplicated(subset=['ID', 'Name'], keep='first')
print(f"\n检查重复行:\n{is_duplicate}")
# 删除重复行
df_no_dups = df_dups.drop_duplicates(subset=['ID', 'Name'], keep='first')
print(f"\n删除重复行后:\n{df_no_dups}")
3. 数据类型转换
有时,数字被错误地存储为字符串,或者日期被存为普通文本。我们需要将它们转换为正确的类型才能进行计算或分析。
Series.astype(dtype, copy=True, errors='raise')
| 参数 | 说明 |
|---|---|
dtype |
(必选)目标数据类型(如 float, int, str)。 |
copy |
(可选)是否返回数据的副本。 |
errors |
(可选)'raise' 遇到无效转换时报错,'ignore' 则保持原值。 |
pd.to_datetime(arg, format=None, errors='raise', infer_datetime_format=False)
| 参数 | 说明 |
|---|---|
arg |
(必选)需要转换的序列、列表或单个日期字符串。 |
format |
(可选)指定日期格式,能显著提升解析速度。 |
errors |
(可选)'raise'、'coerce' 或 'ignore',控制解析失败的处理方式。 |
infer_datetime_format |
(可选)自动推断格式,提高性能。 |
# 假设 'Sales' 列被错误地存为字符串
df_wrong_type = df_sales.copy()
df_wrong_type['Sales'] = df_wrong_type['Sales'].astype(str)
print(f"\n'Sales' 列类型错误的信息:")
df_wrong_type.info()
# 使用 astype() 转换回数值类型,并捕获潜在错误
df_corrected_type = df_wrong_type.copy()
df_corrected_type['Sales'] = df_corrected_type['Sales'].astype(dtype='float64', errors='raise')
print(f"\n'Sales' 列类型修正后的信息:")
df_corrected_type.info()
# 使用 pd.to_datetime() 转换日期字符串
df_corrected_type['Date'] = pd.to_datetime(df_corrected_type['Date'], format='%Y-%m-%d', errors='raise')
print(f"\n'Date' 列类型修正后的信息:")
df_corrected_type.info()
五、分组与聚合:从细节中看全局
groupby 操作是数据分析的基石。它遵循一个“拆分-应用-合并 (Split-Apply-Combine)”的模式:
- 拆分 (Split): 根据某个或某些列的值,将数据拆分成多个组。
-
应用 (Apply): 对每个独立的组应用一个函数(如
sum,mean,count)。 - 合并 (Combine): 将所有组的计算结果合并成一个新的 DataFrame。
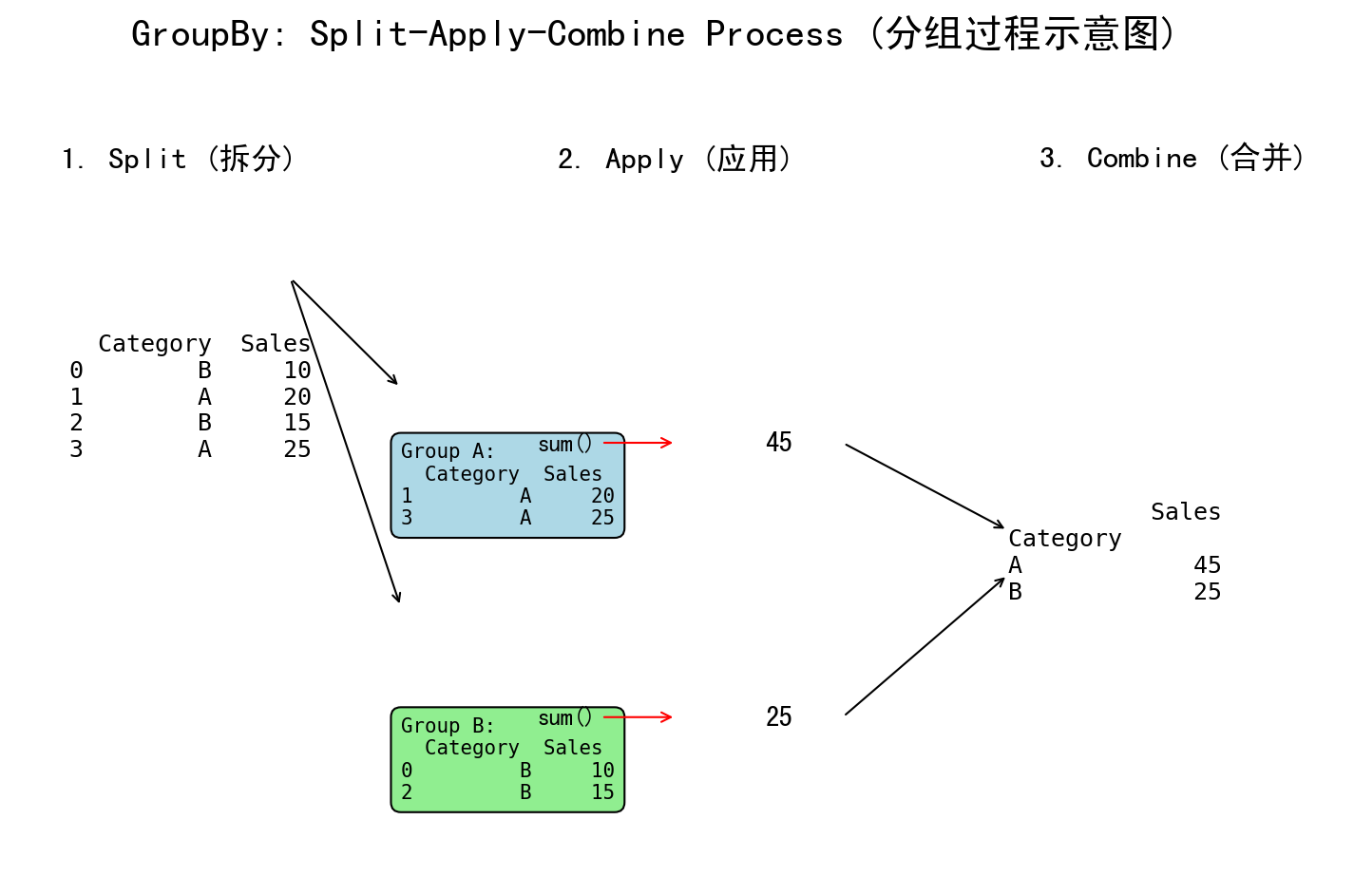
df.groupby(by, axis=0, sort=True, as_index=True, dropna=True)
| 参数 | 说明 |
|---|---|
by |
(必选)用于分组的列标签、列表或字典。 |
axis |
(可选)默认为行分组 (axis=0),也可按列分组。 |
sort |
(可选)是否对分组键排序。 |
as_index |
(可选)为 True 时分组键成为结果的索引。 |
dropna |
(可选)是否忽略分组键为 NA 的行。 |
GroupBy.agg(func=None, *args, **kwargs)
| 参数 | 说明 |
|---|---|
func |
(必选)可以是单个函数、函数列表或列-函数映射。 |
kwargs |
(可选)向聚合函数传递的额外参数。 |
observed |
(可选)针对分类分组键控制是否仅保留出现过的组合。 |
# 目标:按 'Category' 分组,计算每个类别的总销售额和平均销售额
# 1. 按 'Category' 分组
grouped_by_category = df_sales.groupby(by='Category', sort=True, dropna=False)
# 2. 对 'Sales' 列应用聚合函数
agg_results = grouped_by_category['Sales'].agg(['sum', 'mean', 'count'])
print(f"\n按类别分组聚合的结果:\n{agg_results}")
# 更常见的链式调用写法,并使用 reset_index() 将分组键变回列
agg_results_chained = df_sales.groupby('Category')['Sales'].agg(['sum', 'mean']).reset_index()
print(f"\n链式调用并重置索引的结果:\n{agg_results_chained}")
# 按多个列分组:按 'Region' 和 'Category' 分组
agg_multi_group = df_sales.groupby(['Region', 'Category'])['Sales'].sum().reset_index()
print(f"\n按多个列分组聚合的结果:\n{agg_multi_group}")
# 使用命名聚合构建更可读的结果表
agg_named = df_sales.groupby('Region').agg(
total_sales=('Sales', 'sum'),
average_sale=('Sales', 'mean'),
orders=('Sales', 'count')
).reset_index()
print(f"\n命名聚合的结果:\n{agg_named}")
六、合并与重塑:整合多个数据源
1. pd.concat: 堆叠数据
concat 用于沿着一个轴将多个 DataFrame 对象堆叠在一起。
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None)
| 参数 | 说明 |
|---|---|
objs |
(必选)要连接的对象列表或字典。 |
axis |
(可选)0 表示纵向堆叠,1 表示横向拼接。 |
join |
(可选)'outer' 取并集,'inner' 取交集。 |
ignore_index |
(可选)是否重新生成连续索引。 |
keys |
(可选)为拼接结果添加分层索引。 |
df1 = pd.DataFrame({'A': ['A0', 'A1'], 'B': ['B0', 'B1']})
df2 = pd.DataFrame({'A': ['A2', 'A3'], 'B': ['B2', 'B3']})
# 垂直堆叠 (默认 axis=0)
vertical_concat = pd.concat([df1, df2], axis=0, ignore_index=True)
print(f"\n垂直拼接:\n{vertical_concat}")
# 水平堆叠 (axis=1)
horizontal_concat = pd.concat([df1, df2], axis=1, keys=['left', 'right'])
print(f"\n水平拼接:\n{horizontal_concat}")
2. pd.merge: SQL 式连接
merge 用于根据一个或多个共同的键(列)将不同的 DataFrame 连接起来,类似于 SQL 的 JOIN。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, suffixes=('_x', '_y'))
| 参数 | 说明 |
|---|---|
left, right
|
(必选)参与合并的 DataFrame。 |
how |
(可选)连接方式:'inner', 'left', 'right', 'outer', 'cross'。 |
on |
(可选)连接键列名(双方一致时)。 |
left_on, right_on
|
(可选)当连接列名不同时分别指定。 |
suffixes |
(可选)合并后重复列名的后缀。 |
left = pd.DataFrame({'key': ['K0', 'K1', 'K2'], 'A': ['A0', 'A1', 'A2']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K3'], 'B': ['B0', 'B1', 'B3']})
# 内连接 (inner join): 只保留两个表中 key 都存在的行
inner_merge = pd.merge(left, right, on='key', how='inner', suffixes=('_left', '_right'), indicator=True)
print(f"\n内连接结果:\n{inner_merge}")
# 左连接 (left join): 保留左表所有行,右表匹配不上的用 NaN 填充
left_merge = pd.merge(left, right, on='key', how='left', validate='one_to_one')
print(f"\n左连接结果:\n{left_merge}")
3. pivot_table: 数据透视表
数据透视表是一种强大的数据重塑和汇总工具,可以将长格式的数据转换为宽格式,非常适合制作交叉分析报告。
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False)
| 参数 | 说明 |
|---|---|
data |
(必选)输入的长格式数据源。 |
values |
(可选)需要聚合的列。 |
index |
(可选)结果表的行索引。 |
columns |
(可选)结果表的列索引。 |
aggfunc |
(可选)聚合函数,可为函数或列表。 |
fill_value |
(可选)用于填充缺失值。 |
margins |
(可选)是否添加合计行/列。 |
# 目标:创建一个数据透视表
# 行是 'Region', 列是 'Category', 值是 'Sales' 的总和
pivot = pd.pivot_table(df_sales,
values='Sales',
index='Region',
columns='Category',
aggfunc='sum',
fill_value=0,
margins=True,
margins_name='Total') # 用 0 填充缺失的组合,并添加合计
print(f"\n销售数据透视表:\n{pivot}")
实践小结: 你已经掌握了使用 Pandas 进行数据导入、检视、筛选、清洗、聚合和合并的核心技能。这些操作构成了绝大多数数据分析项目的骨架。请务必花时间练习 loc/iloc 的区别、布尔索引的逻辑以及 groupby 的思维模式。下一章,我们将学习如何将这些处理好的数据通过 Matplotlib 进行可视化呈现。